TiDB执行计划
Tidb中想知道SQL在数据库中是怎么执行的,可以和Mysql中一样,使用 EXPLAIN 关键字。
和Mysql不一样的是,Tidb早期版本宣传支持的Mysql版本是5.7(Tidb7.4以后正式支持Mysql8.0)。
但是Mysql8.0中的 EXPLAIN ANALYZE关键字,在TIdb的早期版本中也时支持的。与EXPLAIN不会执行SQL不同,EXPLAIN ANALYZE会执行对应的 SQL 语句,记录其运行时信息,和执行计划一并返回出来。它的输出格式和Mysql8.0中差异较大。
实际应用中,我们一般使用EXPLAIN ANALYZE显示更多的物理执行信息来优化SQL。
一 EXPLAIN ANALYZE列含义
EXPLAIN ANALYZE查询执行计划列含义:
| 属性名 | 含义 |
|---|---|
| id | 算子名,或执行 SQL 语句需要执行的子任务 |
| estRows | iDB 预计会处理的行数 |
| task | 算子位置,cop(TiKV或TiFlash)和 root (Tidb) |
| access-object | 显示被访问的表、分区和索引 |
| operator info | 列可显示诸如条件下推等信息 |
| actRows | 算子实际输出的数据条数。 |
| execution info | 算子的实际执行信息。time 表示从进入算子到离开算子的全部 wall time,包括所有子算子操作的全部执行时间。如果该算子被父算子多次调用 (loops),这个时间就是累积的时间。loops 是当前算子被父算子调用的次数。 |
| memory | 算子占用内存空间的大小。 |
| disk | 算子占用磁盘空间的大小。 |
二 常用SQL优化技巧
- 索引优化,如果使用记录数较多的表的列,那么就要考虑在列上建索引
- 避免全表扫描(Full Table Scan)
- 优化查询条件,避免在列上进行函数操作
- 使用覆盖索引,不用回表,减少IO操作
三 分析优化举例
由于使用hibernate,在享受遍历性的同时,部分SQL常常被拼接的过于臃肿。下面这个SQL就是这样,其中查询字段重复包含了9个表的全部字段,大概有400多个,用省略号代替。
1 | explain analyze |
大致优化分析及优化思路:
检查条件列是否建立索引,对于不能使用索引的,是否可以使用Tiflash优化(实际结果:非大表,非聚合而使用列取,优化不明显,大概在几十ms内)
- 首次优化,大概从7s到2.5s,执行计划如下:
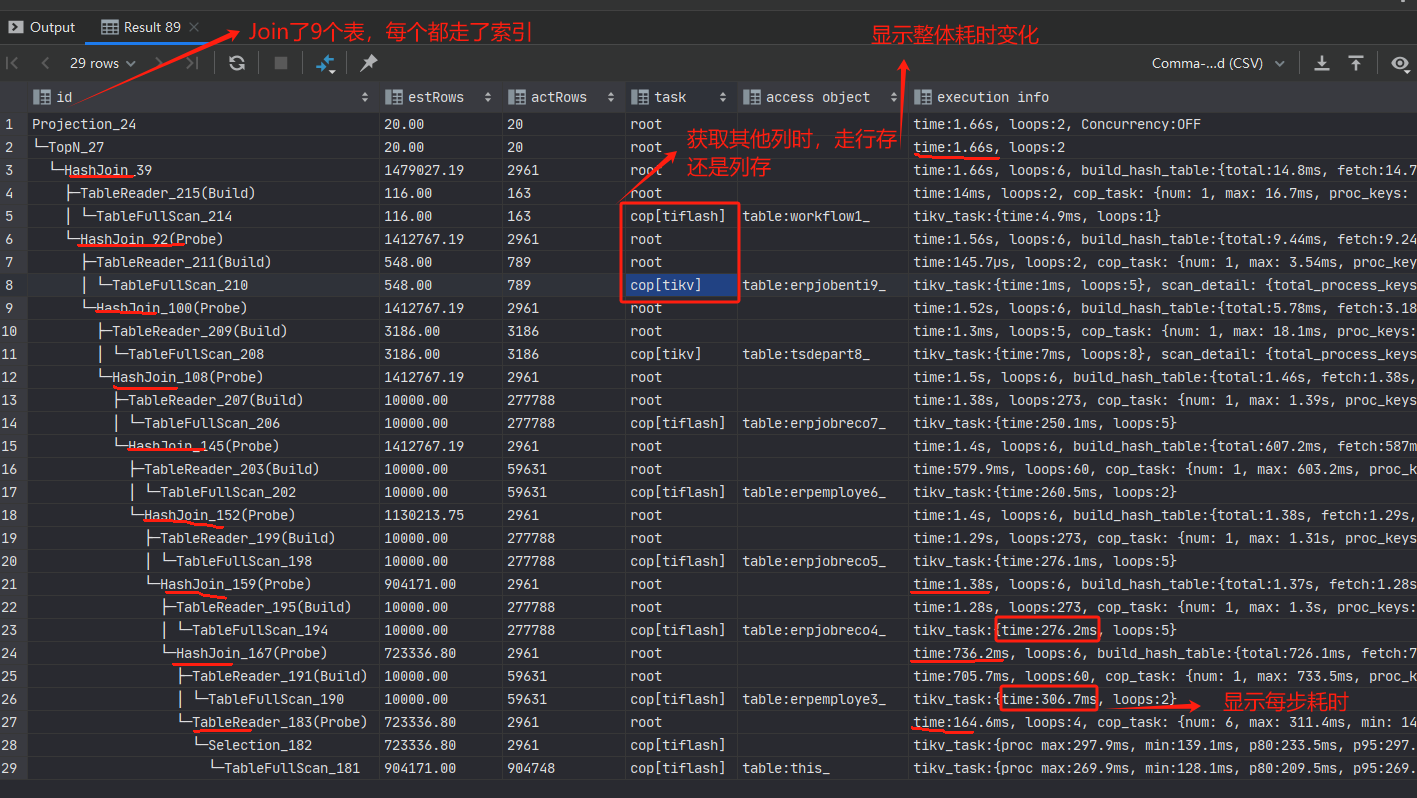
上面提到Hibernate的ENtity拼接导致了很多冗余字段,在执行计划中也展示出来: 只是抓取20条记录,实际却要处理300多M数据。因此,可以
- 优化业务关联,省略无效JOIN
- 根据业务情况,使用同名简短Entity(省去无效JOIN,省去冗余字段)
优化后SQL为:
1 | FROM simple_workflow_record this_ |
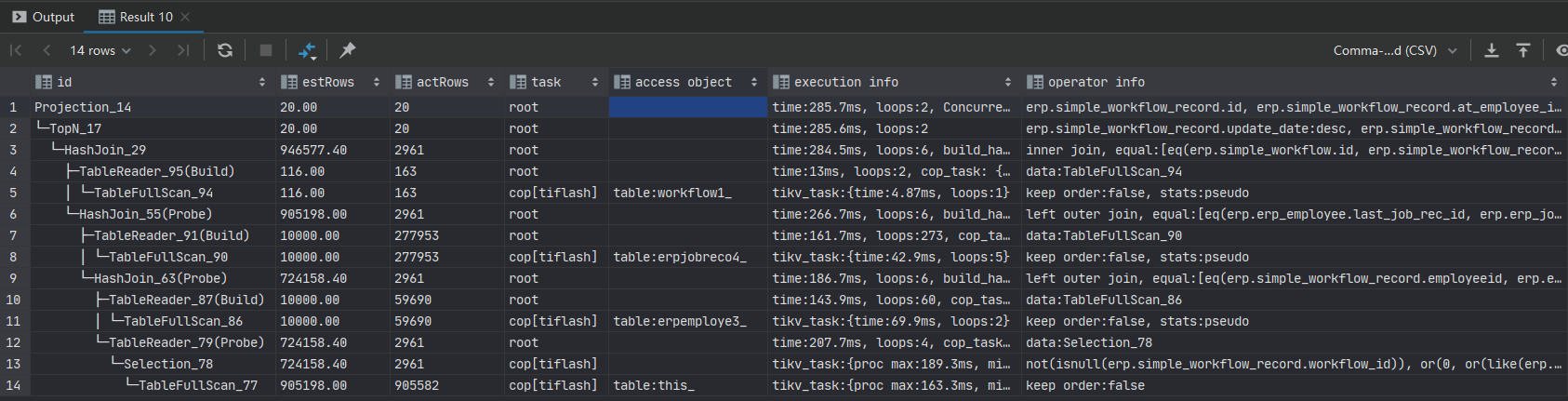
最终优化后执行耗时460ms,执行计划如下:
- ANALYZE TABLE
ANALYZE 语句用于更新 TiDB 在表和索引上留下的统计信息。执行大批量更新或导入记录后,或查询执行计划不是最佳时,建议运行 ANALYZE。
当 TiDB 逐渐发现这些统计数据与预估不一致时,也会自动更新其统计数据。