Redis高级功能
Redis高级功能,绝非一些面试网站说的消息队列、哨兵模式什么的。而是位图、Geo模块、概率数据结构类型等等,它们都是解决特定场景问题的利器。当你明白它们的大致原理和使用方式,那么遇到的时候,你就是最靓的仔 :)
管道pipeline
Redis 流水线是一种通过一次发出多个命令来提高性能的技术,而无需等待对每个单独命令的响应。大量的命令,只需要一次网络交互,这在实际应用中很有用。曾经在一次营销活动中,需要预热数据帮我提升了10倍不止的效率。
以下是用jedis客户端批处理hset存一个map的示例:
1 | private void pipeline(String key, Map fvMap) { |
布隆过滤器Bloom filter
大名鼎鼎的布隆过滤器,其实是一种概率数据结构,用于检查集合中是否存在元素。类似的概率型数据结构,在Redis官网下有一个专栏: Probabilistic概率 ,并且有多重概率型数据结构在不断添加中。比如Top-K(获取排名前K元素)、Count-min sketch(估计数据流中元素的频率)。
原理
首先分配一块内存空间做 bit 数组,数组的 bit 位初始值全部设为 0。
- 加入元素时,采用 k 个相互独立的 Hash 函数计算,然后将元素 Hash 映射的 K 个位置全部设置为 1。
- 检测 key 是否存在,仍然用这 k 个 Hash 函数计算出 k 个位置,如果位置全部为 1,则表明 key 存在,否则不存在
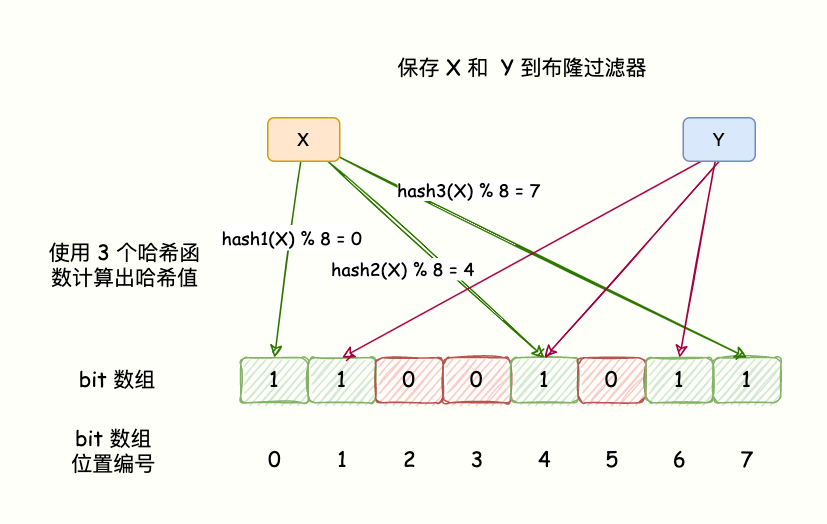
注意:基于以上原理,那么就可以得出1个结论:
如果判定不存在,那么一定不存在;如果判断存在,那么可能不存在。
例:如果v1的hash值落到bit数组的1、2、3,计算v2的hash值对应到2、3。而v1存在,v2不存在,那么判断v2就会有误判。
安装
布隆过滤器并非Redis的自带功能,而是通过插件的方式来支持的。你可以通过docker直接运行打包好了的docker镜像,或者自己编译。
docker方式
1
docker run -p 6379:6379 -it --rm redis/redis-stack-server:latest
自己编译
1
2
3
4
5
6
7apt-get install -y git
cd ~/Redis
git clone --recursive https://github.com/RedisBloom/RedisBloom.git
cd RedisBloom
./sbin/setup
bash -l
make我在自己编译的时候,
./sbin/setup这一步引发的python依赖错误把我劝退了。
[参考] https://cloud.tencent.com/developer/article/1975700
使用
1 | 127.0.0.1:6380> BF.ADD Filter1 a |
参数说明
配置布隆过滤器,如果不配置参数,BF.ADD的时候会使用默认参数
1 | BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}] [NONSCALING] |
- 默认参数值
| error_rate错误率 | capacity容量 | expansion扩容 |
|---|---|---|
| 0.01 | 100 | 2 |
使用注意:
- 布隆过滤器不支持删除,如果需要删除,使用布谷鸟过滤器(Cuckoo)
- 初始容量设计过大会浪费空间,过小虽然会扩容,但会导致实时错误率攀升
Streams流
参考kafka设计,实现了仅追加的数据结构,通常用于可以持久化的消息队列。
Redis为每个流条目生成一个唯一的ID,向流中添加条目是O(1),访问任何单个条目都是O(n)(n是ID 的长度)
版本5以上才有(
info server命令检查)
基本命令
1 | XADD 将新条目添加到流中 |
基本使用
1 | # * 号表示服务器自动生成 ID,后面顺序跟着一堆 key/value |
位图BitMap
位图不是实际的数据类型,而是在 String 类型上定义的一组面向位的操作,该类型被视为位向量。由于字符串是二进制安全 blob,其最大长度为 512 MB,因此它们适合设置多达 2^32 个不同的位。
基本命令
1 | SETBIT 将提供的偏移位设置为 0 或 1 |
基本使用
1 | 127.0.0.1:6380> setbit key 1 1 |