一次OOM分析
世界上没有无缘无故的爱,也没有无缘无故的恨。
OOM了,肯定是要找到元凶的!
一、问题描述
(tomcat的OOM信息会在catalina.log日志文件和catalina.out日志文件打印)

OOM的时候记录并dump堆文件,JVM启动参数需要加上:
1 | # 指定生成Dump文件的异常类型 |
如果是运行中需要分析堆,也可以使用jmap主动生成
jmap -dump:format=b,file=heap_dump.hprof $PID
二、问题思路
生成堆文件后,需要分析工具。可以采用开源的Mat
注意:
最新版本的1.15要求最少是JDK17, 我用的是1.10 可以在JDK8上运行
Mat运行要求的内存空间较大,实际根据堆文件大小来调整 MemoryAnalyzer.ini 配置文件 。
我堆文件有25G,实际我分配了20G的最大堆才导入成功
如果服务器上内存够用的话,可以直接生成相关报告:
./ParseHeapDump.sh /data/log/erp_202312.hprof org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
三、问题分析
好不容易导入堆文件后没找到重点,在参考一下别人怎么玩的之后,通两个功能(排列大对象+内存泄露分析)就找到元凶。
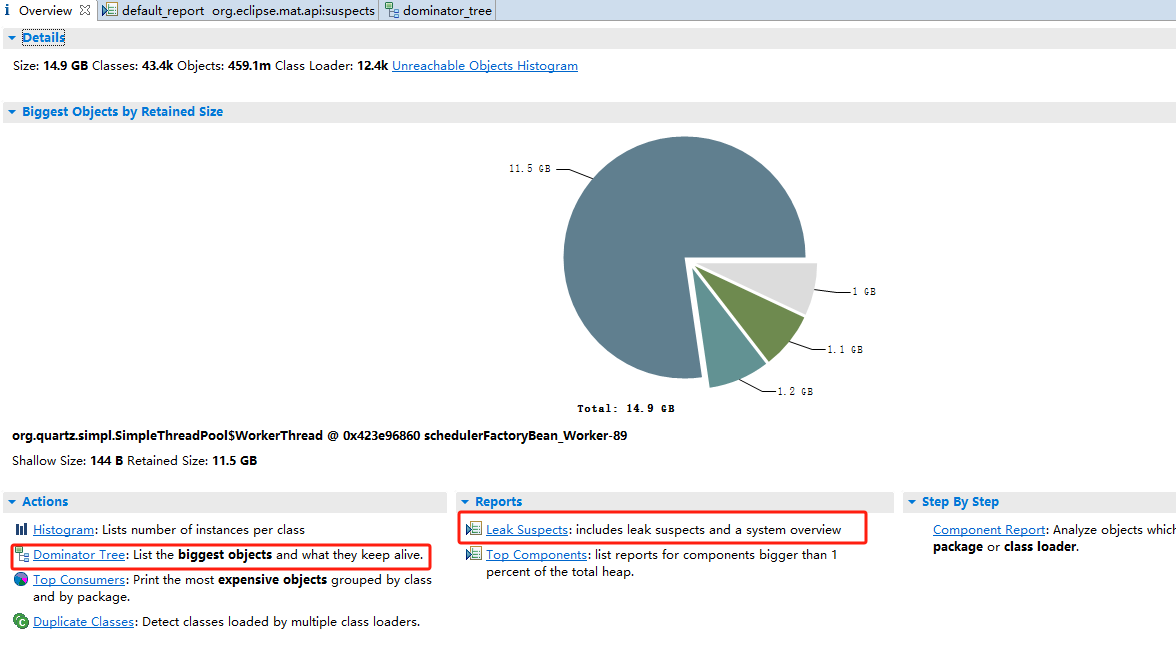
3.1 锁定上下文
首先,对象名称是一个定时任务线程池的线程。在圆饼上左键看看大对象的上下文信息,可以找到这个定时任务具体执行类是哪个
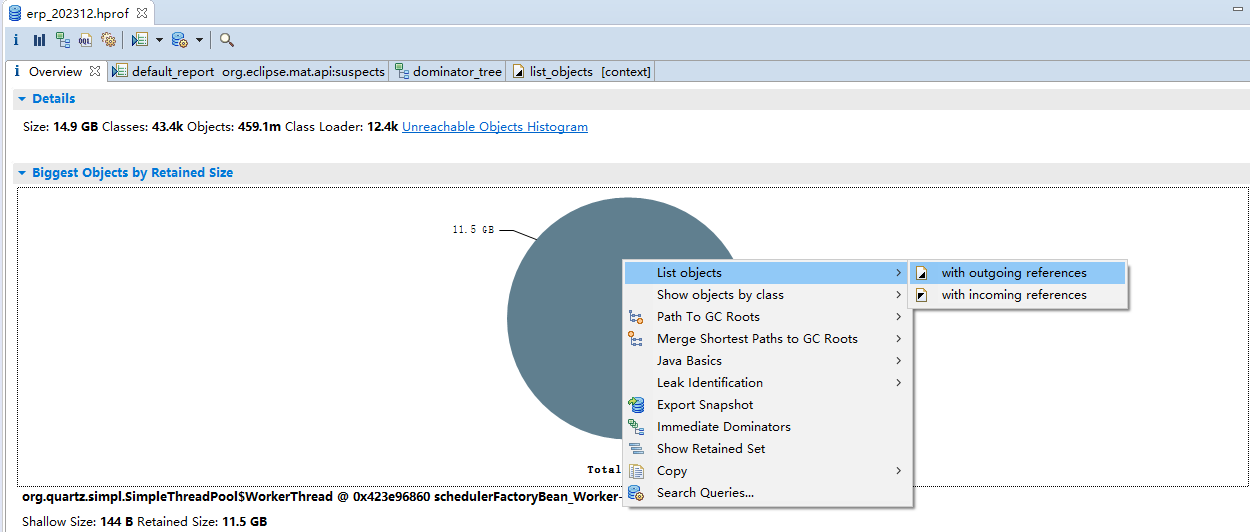
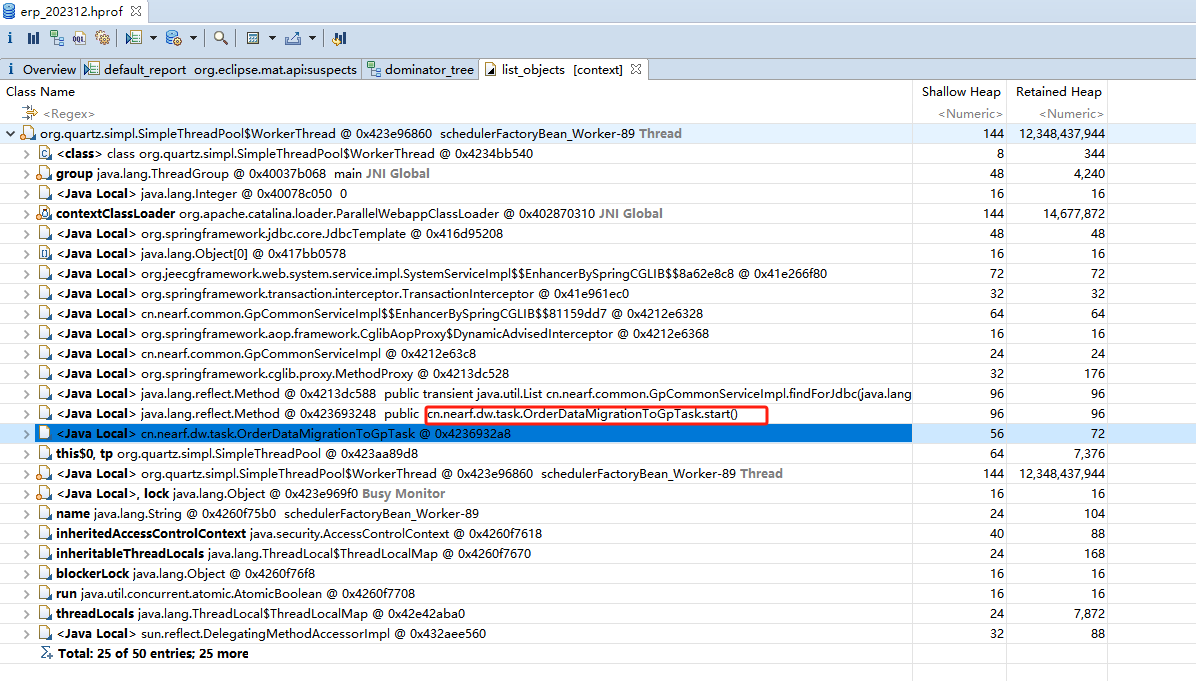
3.2 大对象分析
然后,选择大对象分析,发现两个List占用了11.5G,我最大堆分配的是15G。这里估计就是原因所在了
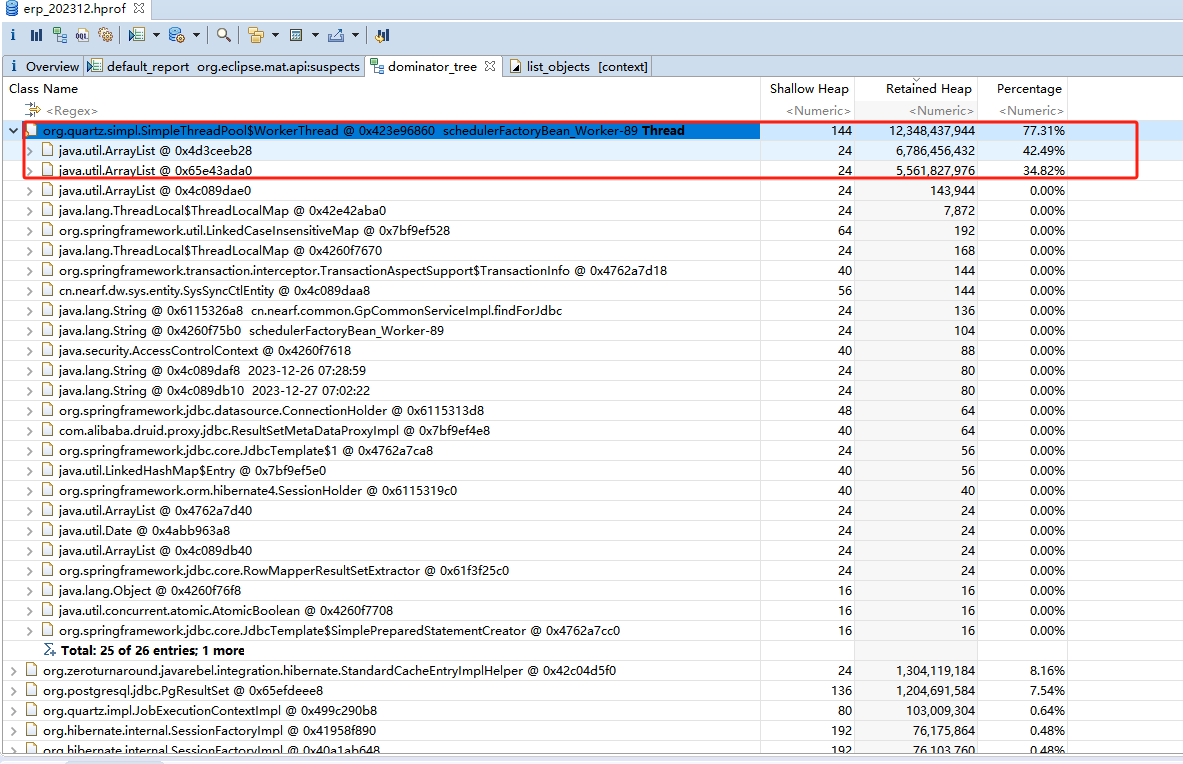
3.3 内存泄露分析
使用内存泄露分析,发现大对象List是哪里出现的
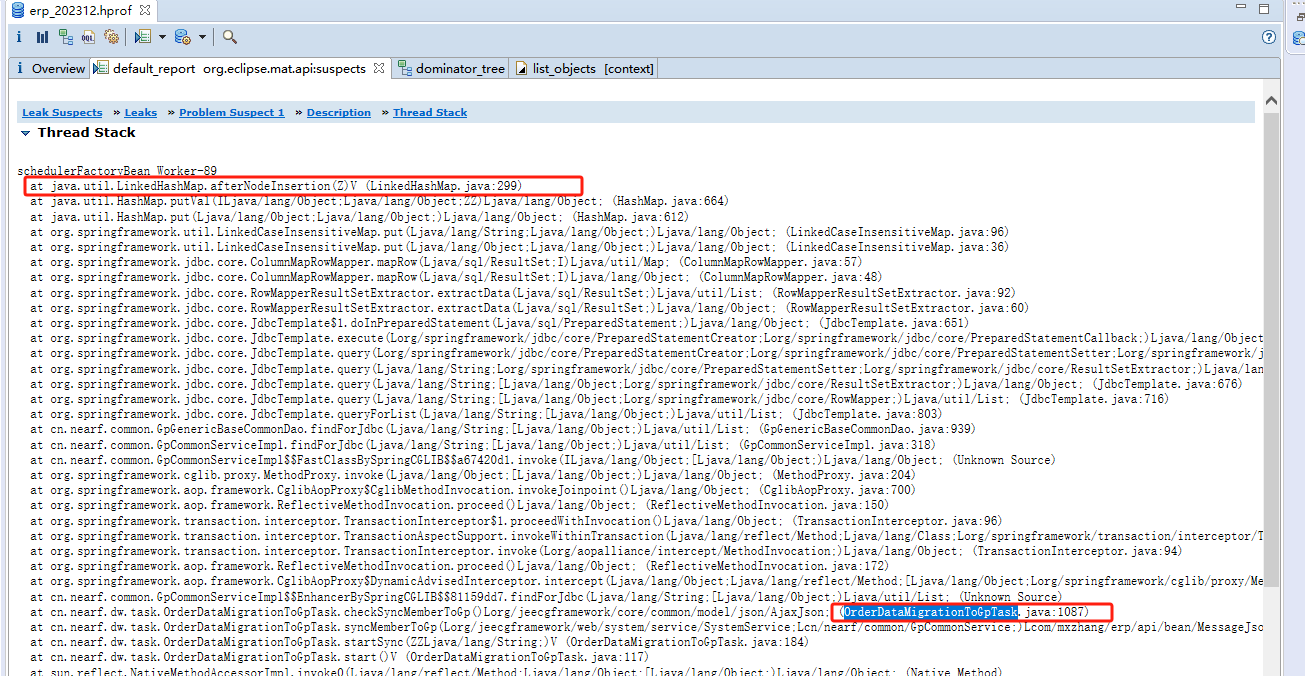
3.4 结合代码验证
反过来再参考代码和日志 ,印证了服务挂掉的就是这个位置
(这里看起来只取了一堆ID,实际上每个值都是一个LinkedHashMap,数据中大概每个List都是2000w):
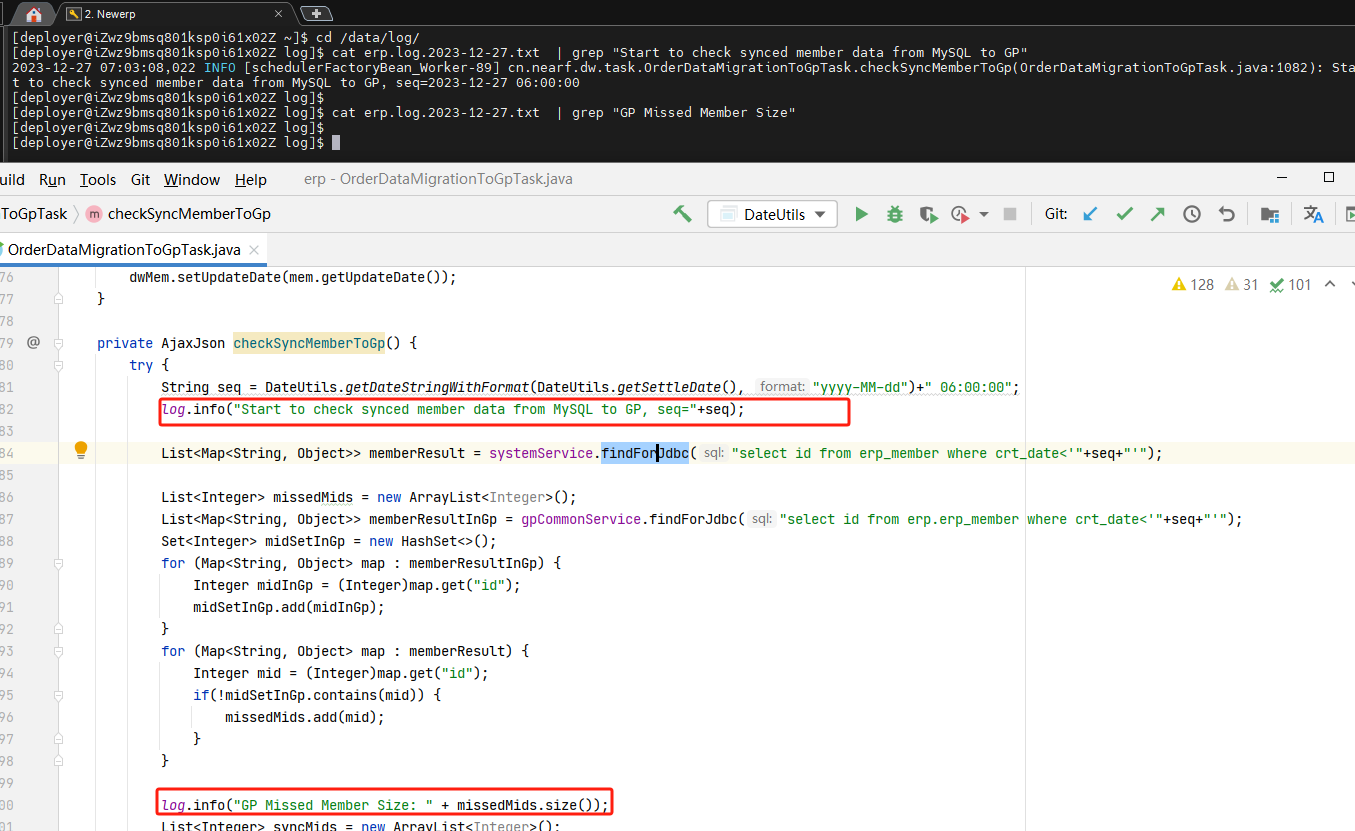
四、问题解决
原代码的JdbcService其实还是使用Jdbctemplate的RowMapper进行行数据提取,生成了大量的中间Map。
可以使用query(String sql, RowCallbackHandler rch), 也可以自定义ResultSetExtractor,主动提取id,省掉中间Map
参考: